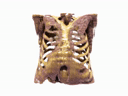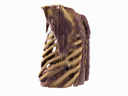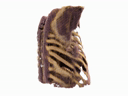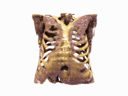
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
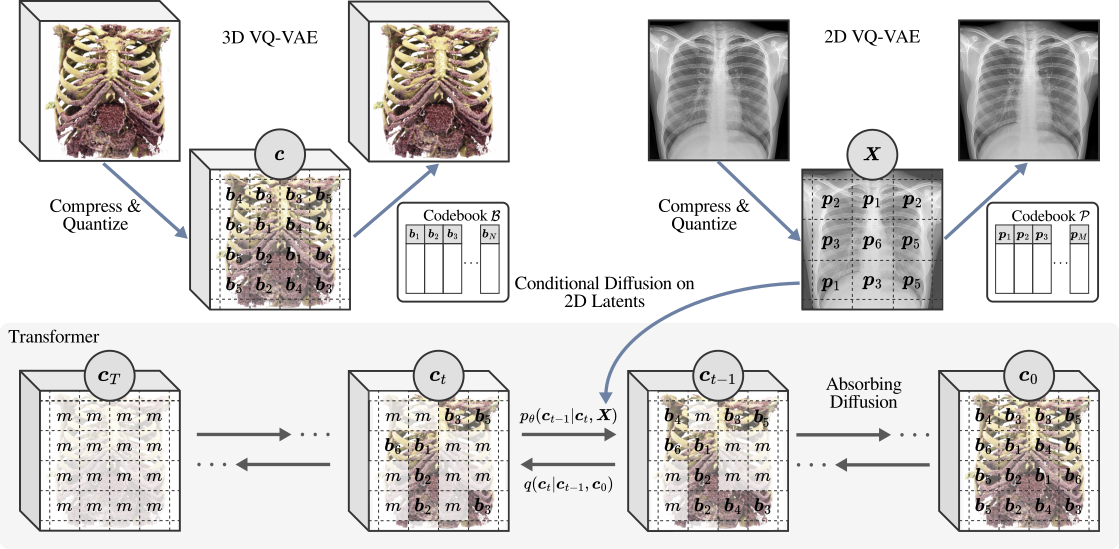
Our approach allows 2D to 3D translation from unaligned data by independently learning discrete information-rich codebooks for both domains with Vector-Quantized VAEs. New 3D samples are then synthesized by modeling the conditional probability given few X-rays with a discrete diffusion model parameterized by an unconstrained transformer.
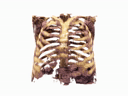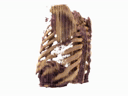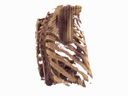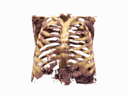
Generating CT from X-rays has potential for reducing patient radiation exposure and cost. In chest CT experiments, our model accurately separates soft tissue and bone without being explicitly trained to decompose them. Compared to competive methods, our results are less noisy with distinct anatomical structures.
Our approach can model objects within passenger bags, especially useful in security screening for detecting prohibited items. Yet, 3D reconstruction in this context is challenging due to diverse baggage types (suitcases, backpacks) and unpredictable, compactly arranged items.



@inproceedings{coronafigueroaa23unaligned,
author = {Corona-Figueroa, Abril and Bond-Taylor, Sam and Bhowmik, Neelanjan and Gaus, Yona Falinie A. and Breckon, Toby P. and Shum, Hubert P. H. and Willcocks, Chris G.},
booktitle = {Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision},
series = {ICCV '23},
title = {Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers},
year = {2023},
month = oct,
publisher = {IEEE/CVF},
location = {Paris, France},
}